生产环境部署ELK7+ES冷热数据分离
需求整理
当前公司还没有日志收集系统,.线上故障排错需要开发和运维人员通过跳板机登陆到业务服务器去查看日志,如果集群下服务器节点较多,可能需要登陆到每一台服务器才能找到准确的故障信息.这种方式会带来许多问题:
- 效率低下
- 需要给研发人员分配生产服务器账号,有安全隐患
- 查看日志的方式极为麻烦,复杂
- 每台业务服务器需要大容量磁盘保存日志文件
Elasticsearch冷热数据分离
公司目前共有4个APP产品,每天的nginx日志+业务日志+php日志总共预计在1.5T左右.一周的日志数据量在10T左右.Elasticsearch规划了20T的SSD磁盘用来一周的日志数据(7天日志+1个副本).这些数据保存在Elasticsearch的热节点.
考虑到1周以后的日志数据查询频率非常低,所以可以将这部分的日志迁移和归档到Elasticsearch的冷节点.并且冷节点日志无需索引.所以预留了10T的SAS磁盘保留1周的冷数据.
总共是20TSSD磁盘的热节点和10TSAS机械磁盘的冷节点
Elasticsearch集群节点规划
- 热节点规划
ES集群的DATA节点负责保存收集到的日志数据,索引,整理和查询日志等工作.所以data节点对硬件资源要求较高.
计划使用3台物理服务器(VMware虚拟化集群),每台物理机的配置是32核134G,每台物理机有2个VM.一共计划6个elasticsearch的节点.
每个物理服务器上使用4块1.92T的SSD磁盘.平均每个VM虚拟机可以使用16核67G内存4TSSD磁盘.
后期又增加了一台服务器,配置为16核48G内存2TSSD
7个节点一共有20TSSD磁盘空间,刚好满足7天的日志数据的需求.
为了避免磁盘IO竞争.每个节点使用独立的单块SSD磁盘,
- 冷节点规划
集群冷节点可以适当放低硬件资源.计划使用2台VM作为ES冷节点.每台服务器为8核32G.为了更充分利用带宽和CPU资源.以及合理规划ES的节点角色.冷节点同时又作为集群的master节点和logstash的角色.
这样热节点就有充分资源作为data角色
ELK架构规划
为了ELK的高性能和数据传输安全性,完整的架构如下:
1 | Filebeat------>logstash------->Elasticsearch-------->kibana------->nginx |
以下是各组件作用介绍:
- Filebeat: 轻量级的日志收集Agent,部署在每台业务服务器
- logstash(5节点): 从filebeat费日志数据,并对数据进行加工处理,传输给ES.由于集群资源本身的稳定和健壮,logstash并不需要使用持久化数据特性.
- Elasticsearch(7节点):保存和索引数据.7个热节点和2个冷节点
- kibana:从Elasticsearch获取数据并在web界面展示
- nginx: kibana的代理服务器
官网要求ELK组件必须使用相同的版本,这次部署的是ELK的最新版.7.7版本
ELK服务器信息
| 主机名 | IP地址 | 操作系统 | 运行组件 | 功能 | 配置 |
|---|---|---|---|---|---|
| idc-function-elk01 | 172.16.20.101 | CentOS7.7 | logstash,es | logstash节点,data,master节点 | 16核80G3.84TSSD |
| idc-function-elk02 | 172.16.20.102 | CentOS7.7 | es | ES data节点 | 16核54G3.84TSSD |
| idc-function-elk03 | 172.16.20.103 | CentOS7.7 | logstash,es | logstash节点,data节点 | 16核80G3.84TSSD |
| idc-function-elk04 | 172.16.20.104 | CentOS7.7 | es | ES data节点 | 16核54G3.84TSSD |
| idc-function-elk05 | 172.16.20.105 | CentOS7.7 | logstash,es | logstash节点,data节点 | 16核80G3.84TSSD |
| idc-function-elk06 | 172.16.20.106 | CentOS7.7 | es | ES data节点 | 16核54G3.84TSSD |
| idc-function-elk07 | 172.16.20.107 | CentOS7.7 | es | ES data节点 | 16核54G1.92TSSD |
| idc-function-elk08 | 172.16.20.108 | CentOS7.7 | logstash,es | ES的master,冷节点,logstash节点 | 8核32G9.6TSAS |
| idc-function-elk09 | 172.16.20.109 | CentOS7.7 | logstash,es | ES的主master节点,冷节点,logstash节点 | 16核32G5TSAS |
| idc-function-docker | 172.16.20.30 | CentOS7.7 | nginx | 一台现有的服务器 | |
| idc-function-elk10 | 172.16.20.110 | CentOS7.7 | logstash,es | 仅仅作为ES的master节点,,logstash节点 | 8核8G200GSAS |
部署安装
部署elasticsearch
- 部署JAVA环境.
官网要求需要JDK8或者11版本.这里部署的是11版本.在Oracle有rpm包.
1 | [work@idc-function-elk01 ~]$ java -version |
- 安装elasticsearch
官网的yum安装非常慢.先从elasticsearch中文社区下载rpm包.然后使用yum本地安装
中文社区下载中心:https://elasticsearch.cn/download/
- 配置elasticserch
1 | #以下是ES的配置文件 |
优化系统和elasticsearch配置
- 优化内核参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39[root@idc-function-elk01 ~]# cat /etc/sysctl.conf
net.ipv4.ip_forward=1
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
vm.swappiness = 0
net.ipv4.neigh.default.gc_stale_time=120
net.ipv4.conf.all.rp_filter=0
net.ipv4.conf.default.rp_filter=0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce=2
net.ipv4.conf.all.arp_announce=2
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
kernel.core_uses_pid = 1 #追加进程号到core文件名中
fs.suid_dumpable = 2 #确保设置属主的进程也可以生成core文件
kernel.core_pattern = /tmp/core-%e-%s-%u-%g-%p-%t #指定core文件生成的位置和文件名规则。
vm.overcommit_memory = 1
net.ipv4.conf.lo.arp_announce=2
kernel.sysrq=1
fs.file-max=6553500 #最大文件句柄
fs.nr_open=6553500 #最大文件句柄
net.core.somaxconn = 65535
vm.max_map_count=262144 #ES官网推荐
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 0
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_timestamps=0
net.ipv4.tcp_fin_timeout=30
net.ipv4.ip_local_port_range = 10000 65000
net.nf_conntrack_max = 655360
net.netfilter.nf_conntrack_tcp_timeout_established = 1200- 设置文件句柄,内存
1
2
3
4
5[root@idc-function-elk01 ~]# cat /etc/security/limits.conf
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
* soft nofile 655360
* hard nofile 655360- 关闭Selinux和防火墙
1
2
3
4
5
6
7
8systemctl stop firewalld
systemctl disable firewalld
setenforce 0
[root@idc-function-elk01 ~]# cat /etc/selinux/config
SELINUX=disabled- 创建目录,并且修改权限
1
2
3
4
5[root@idc-function-elk01 ~]# ll /data/elasticsearch/ -d
drwxr-xr-x 3 elasticsearch elasticsearch 27 May 25 23:08 /data/elasticsearch/
[root@idc-function-elk01 ~]# ll /data/logs/elasticsearch/ -d
drwxr-xr-x 2 elasticsearch elasticsearch 4096 May 26 00:00 /data/logs/elasticsearch/- 修改elasticsearch的systemctl启动文件,加入下面这一行:
1
2
3
4
5[root@idc-function-elk01 ~]# cat /usr/lib/systemd/system/elasticsearch.service
#新增这一行.否则启动的时候会提示在配置文件中开启了bootstrap.memory_lock: true.但是系统中没有检测到配置
#unlimit memory
LimitMEMLOCK=infinity- 修改elasticsearch的JVM内存
1
2
3
4[root@idc-function-elk01 ~]# cat /etc/elasticsearch/jvm.options
-Xms32g
-Xmx32g- 启动elasticsearch
1
2systemctl enable elasticsearch
systemctl start elasticsearch
Elasticsearch集群监控工具
这里推荐使用cerebro工具,是一个独立的小工具,无需安装到es插件.具体使用方法请参考:github项目地址
启动cerebro后.访问cerebro的9000端口.可以看到ES集群状态监控界面,界面还挺不错
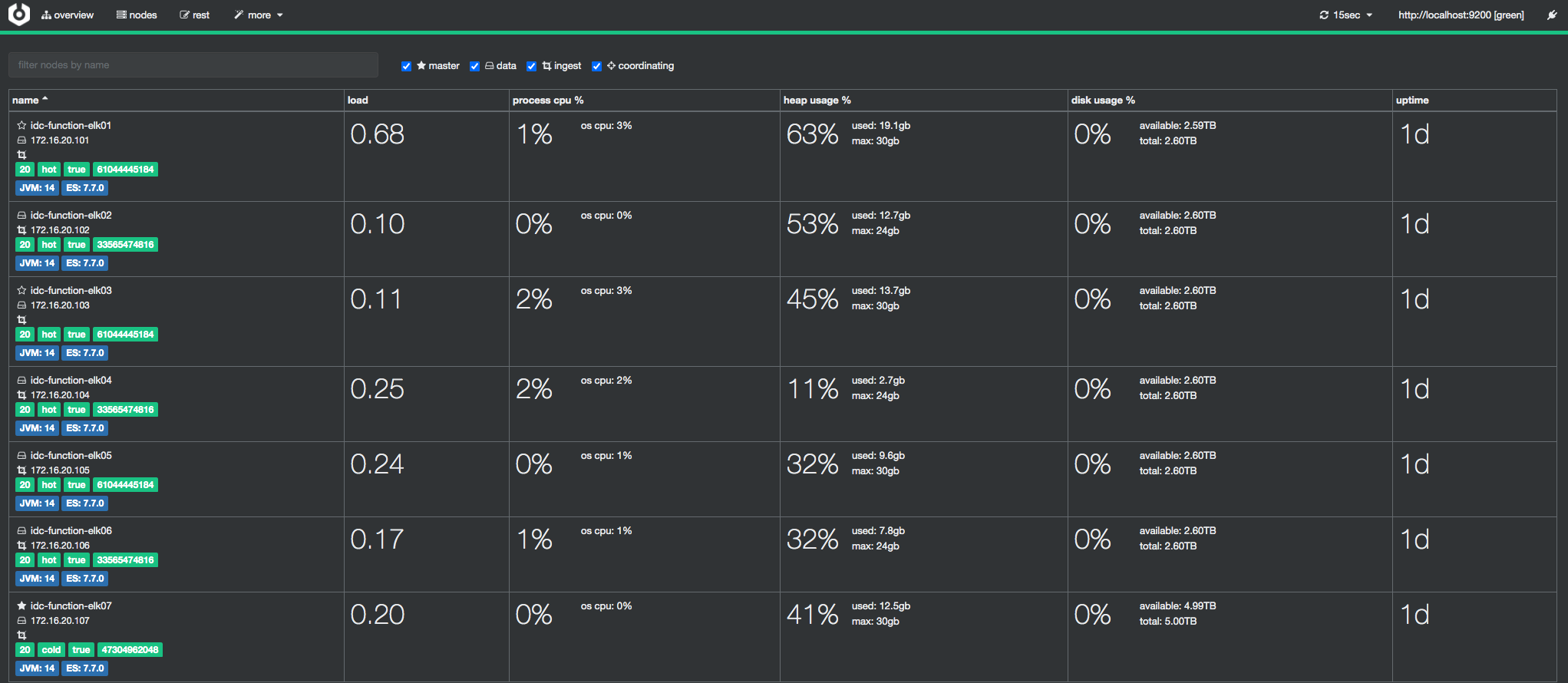
从上面的集群截图中可以看到,每个ES节点都有
hot或者cold标签以区分节点属性.这就说明冷热节点属性配置正常
但是每次登陆cerebro都需要选择连接的ES节点.无法实现登陆自动连接.这非常不方便,我在github上提交了相关issue.得到回复是使用以下URL: http://localhost:9000/#/overview?host=http:%2F%2Flocalhost:9200
所以.可以配置Nginx反向代理:
1 |
|
172.16.20.101:9000这个为cerebro所在服务器.localhost:9200是同台服务器的ES节点.如果ES节点为其他服务器,使用IP地址指定即可
部署logstash
logstash也是运行在JVM的java环境中.安装方法和ES一样.
- 配置logstash文件
1 | [root@idc-function-elk01 ~]# vim /etc/logstash/logstash.yml |
- 修改JVM内存
1 | [root@idc-function-elk01 ~]# vim /etc/logstash/jvm.options |
- systemctl启动logstash
1 | service logstash start |
部署到其他服务器
如果通过克隆或者模板的方式部署到其他服务器,那么ES集群应该会报错,提示无法将节点加入到集群中.这是因为集群中所有节点的data数据目录拥有同一个ID.
1 | can't add node {idc-function-elk03}{dt57hBjCQ9uCAp8G6sxJYw}{7-s_05ZMSl6CtpmMZGZEUA}{172.16.20.103}{172.16.20.103:9300}{dilmrt}{ml.machine_memory=61044445184, ml.max_open_jobs=20, xpack.installed=true, transform.node=true}, found existing node {idc-function-elk01}{dt57hBjCQ9uCAp8G6sxJYw}{biZPCqjCSx-PX3eU-CquUw}{172.16.20.101}{172.16.20.101:9300}{dilmrt}{ml.machine_memory=61044445184, ml.max_open_jobs=20, xpack.installed=true, transform.node=true} with the same id but is a different node instance |
删除data数据路径下的内容,然后重启ES.等待集群自动同步
1 | [root@idc-function-elk03 ~]# rm -rf /data/elasticsearch/nodes |
kibana安装
安装方式非常简单,直接下载rpm包安装即可.安装完成后修改/etc/kibana/kibana.yaml配置文件.新增以下配置.将kibana的web界面改为中文:
1 | i18n.locale: "zh-CN" |
我这里是采用rpm包安装,如果是其他安装方式,请自行寻找配置文件路径
nginx反向代理配置
1 | server { |
安装filebeat.
对于有supervisor的服务器,采用二进制安装,否则使用rpm包安装
二进制包下载地址:http://repo.doweidu.com/ELK/filebeat-7.7.0-linux-x86_64.tar.gz
rpm包下载地址:http://repo.doweidu.com/ELK/filebeat-7.7.0-x86_64.rpm

