记一次生产ELK性能优化
ES上线后遇到一些问题:
一.内存压力过高
目前ES节点的有两种规格内存.
80GB内存(节点同时运行了Logstash,分配了16G给logstash).
54GB内存(只运行ES,并且只作为data节点)
ES的JVM内存从32G下降到28G.建议JVM内存是总物理内存的一半左右,
节点内存使用情况如下:
1 | "mem": { - |
建议: ES节点内存建议配置高一点,虽然ES的JVM内存最大不超过32G.但是在其他方面仍然很吃内存
二.索引字段数
ES的单个索引默认最大字段数量是1000个.当超过这个字段数量时,会拒绝字段映射.
1 | [2020-08-14T10:44:10,605][INFO ][o.e.a.b.TransportShardBulkAction] [idc-function-elk01] [logstash-mg-tc-netrcd-gateway-2020.08.14][0] mapping update rejected by primary |
此时可以在索引模板中,修改默认字段数量.
1 | PUT _template/logstash |
三.ES线程和队列优化
ES日志有部分警告信息:
1 | [2020-08-14T10:15:06,151][WARN ][o.e.c.r.a.AllocationService] [idc-function-elk01] failing shard [failed shard, shard [logstash-msf-internal-access-2020.08.14][0], node[3uwnN_KEQGiywi |
编辑/etc/elasticsearch/elasticsearch.yml配置文件.新增如下配置:
1 | thread_pool: |
同时,修改/etc/logstash/logstash.yml配置文件.修改如下配置
1 | pipeline.batch.size: 10000 |
以上这些配置都需要不断的调试,修改,观察,找到最适合的一个范围和效果
四.集群最大分片(shard)数
今天收集新的日志报错,logstash日志内容如下
1 | [2020-08-24T10:32:41,009][WARN ][logstash.outputs.elasticsearch][main][7ca4981ae091d6b8f604e5695405b2c74a9cb7fc4a72b338be4e2ede66a04d7d] Could not index event to Elasticsearch. {:status=>400, :action=>["index", {:_id=>nil, :_index=>"logstash-hsq-search-netrcd-2020.08.24", :routing=>nil, :_type=>"_doc"}, #<LogStash::Event:0x4a0b491>], :response=>{"index"=>{"_index"=>"logstash-hsq-search-netrcd-2020.08.24", "_type"=>"_doc", "_id"=>nil, "status"=>400, "error"=>{"type"=>"illegal_argument_exception", "reason"=>"Validation Failed: 1: this action would add [14] total shards, but this cluster currently has [8998]/[9000] maximum shards open;"}}}} |
看日志关键字发现当前集群总共分片数是8998个,如果再加上14个分片,那么就超过了最大的9000个.
14和9000个分片是怎么来的?
当前ES集群中有7个热节点,每个索引分片数量是7个,副本数是1..也就是说一个索引就要14个分片(包括副本)
另外,集群中还有2个冷节点,总共是9个节点.从Elasticsearch v7.0.0 开始,集群中的每个节点默认限制 1000 个shard.所以集群所有节点总共是9000个shard(分片)
解决方案
1.每个索引(Index)分配多少个分片(shared)合适?
配置Elasticsearch集群后,对于分片的数量通常比较难确定.分配过小或者过大对性能都不好.实际上每个分片都会消耗硬件资源:
- 由于分片本质上是Lucene索引,因此会消耗文件句柄,内存和CPU资源。
- 每个搜索请求都将触摸索引中每个分片的副本,当分片分布在多个节点上时,这不是问题。当分片争夺相同的硬件资源时,就会出现争用并且性能会下降。
我个人理解一般设置分片数量有几个方向可以考虑
- 由于Elasticsearch的最大JVM一般在30-32G.所以一个分片的数量不能超过30G大小.如果一个索引最大是200G.那么就需要分片7个分片.
- 最好是按照日志创建索引,可以按天,或者周,甚至月来创建索引,如果一个月的日志太大,那么就按天创建索引
- 分片数量的配置最好是基于当前的日志量级,集群节点数量评估.或者可以规划为可以预见的增长幅度评估,千万不能盲目的为一年或者2年以后的日志量分配资源
- 如果不能确定索引容量,或者对于分片设置完全没有概念和把握,那么建议按照ES集群节点数量设置分片,有多少个节点,就设置多少分片,后期再观察和考虑是否需要增加或删减
生产环境中,最好设置为1个副本.副本有助于加速查询和健壮高可用行,但是也会占用磁盘容量空间,没必要设置2个或以上的副本.如果是做了冷热分离,对于冷数据如果没有太大的安全性要求,也可以不设置副本
2.每个节点的
maximum shards open设置为多大合适
根据以下几个指标来评估:
1.当前集群的shard分片数
2.当前集群索引量
3.索引保存时间
以我们生产集群为例,当前集群共有7个热节点,每个索引7个分片.每节点是一个分片.每天是55个索引,加上副本是110个索引,也就是每个节点,每天有110个shard分片.
热节点索引保留14天,单节点总共是110*14=1540个Shard.预留20%的空间,也就是1848个分片.所以给每个节点分配1800-2000个分片比较合适
另外,集群中还有2个冷节点.超过14天的索引会自动迁移到热节点(没有副本),并且保留14天后删除.所以冷节点14天总共分片数是55*7*14=5390个Shard.分摊到2个节点,平均每个节点的Shard是2695..留出20%的空间,每节点的Shard为3234.
经过评估下来,ES热节点每节点Shard数量2000,冷节点3500
编辑ES配置文件,添加以下配置,修改每节点的Shard数量
热节点:
cluster.max_shards_per_node: 2000冷节点:
cluster.max_shards_per_node: 3500
以下是Ansible发布模板
1 | {% if es_role is defined and es_role == 'hot' %} |
重启ES后并没有生效.临时在Kibana的dev tool中设置:
1 | PUT /_cluster/settings |
设置立即生效,在ELK集群面板中,总的shard分片数超过了9000的最大值,已经达到9,376 shards,
博客参考:https://studygolang.com/articles/25396
五.分片严重不均衡
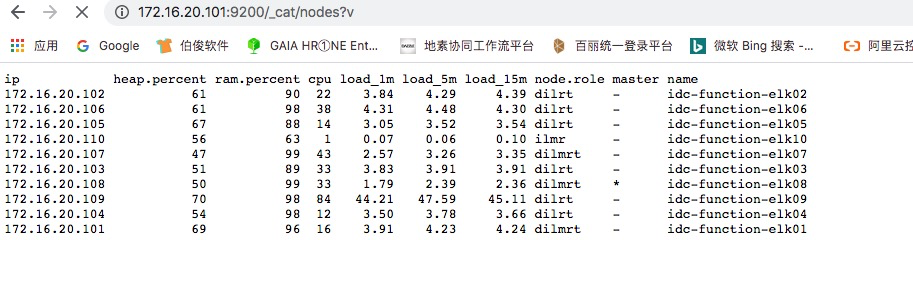
ES集群运行了将近一个月后,出现了分片验证不均衡的现象.当前7个Hot节点中,每个索引一共有7个分片,但是我们发现大部分索引的7个分片全部写入到ELK09这个节点,其他节点没有分配任何分片.如下图所示:

即使将elk09这个节点的磁盘警戒线和最高水位线下调到50%和80%,但是仍然不起作用,磁盘使用率依然上升到90%以上.
也尝试过,严格限定每个索引每节点最大分片数4个,但是ES会将所有4个分片全部写入到ELK09节点
1 | PUT _template/logstash |
之所以设置为4个,是因为每个索引7个分片在14天后会自动迁移到ES冷节点,而一共2个冷节点,所以每个节点4分片.(冷数据没有副本)
观察nodes节点,elk09这个节点的内存,CPU,负载等各指标相比其他节点都高出一大截
故障原因:
故障原因在于其他热节点(elk01-elk06)有2块1.92T的SSD磁盘,总容量3.4T,这台elk09节点只有一块磁盘1.92T的SSD磁盘..这台elk09节点的磁盘容量只有其他节点的一半.
ELK默认是平均分配分片在节点中.当ES中数据较少时,分片会平均分配到各节点中
1 | 1245 759.7gb 1tb 3.9tb 4.9tb 20 172.16.20.108 172.16.20.108 idc-function-elk08 |
但是当索引数据越来越大,elk09磁盘由于警戒线和水位线设置,所以索引分片更多写入到elk01-06这些节点,这就造成elk09节点上的分片数量和其他节点相比差距越来越大.
下图是故障发生时,可以看到每个节点的分片数在2787左右.但是ELK09这个节点的分片在2155个.
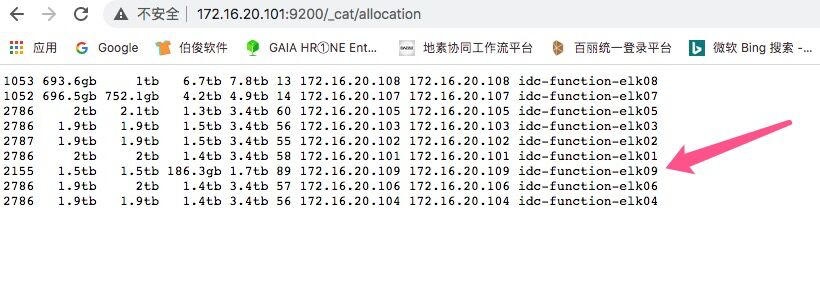
这就导致ES为了平衡各节点分配数量,将新索引的分片集中全部写入到elk09这个节点,以求集群各节点分片数量平衡,从而忽略了节点的磁盘使用率和硬件资源状态.
解决办法
有以下3种解决办法可以参考
1.给elk09添加一块同容量SSD磁盘,这样所有节点的磁盘容量一样,这也是最根本的解决办法
2.适当减少ES的索引保留天数,减少数据量,使得elk09单节点总数据量不超过单块磁盘容量(1.92T)中的50%左右区间.
3.调整集群参数cluster.routing.allocation.balance.shard和cluster.routing.allocation.balance.index.这2个值越大,集群更倾向于在集群中平均负载分片,所以这2个需要调小,具体什么值合适,需要不断的观察和测试.
关于这2个参数的介绍可以参考官网或者博客:
https://www.bookstack.cn/read/ELKstack-guide-cn/elasticsearch-principle-shard-allocate.md

