Kubernetes—-pod原理
开篇
Pod是kubernetes项目中最小的API对象,是原子调度单位.我们之前学习过很多Linux容器,Docker方面的知识.那Kubernetes为什么不使用容器作为调度单位,而是要将容器封装成一个Pod?
要探讨这个问题,我们需要深入研究一下Kubernetes的设计思想和工作原理.
容器本质
通过之前Docker的原理学习,我们知道容器的本质到底是什么? 容器的本质是进程.容器的镜像就像是这个进程的安装包.一键启动这个镜像,就相当于用这个安装包启动了一个进程(PID为1).那么Kubernetes呢?
Kubernetes就是操作系统! 负责所有容器的编排和管理
但是,在一个操作系统里,进程并不是孤苦伶仃的单独运行的,而是以进程组的方式,多个进程同时在一起运行.这些进程存在着”进程和进程组”的关系,他们之间有非常密切的写作关系,使得他们必须部署在同一台机器上.
由于受限于容器的”单进程模型”.一个进程组下的不同进程可能需要制作成多个不同的容器,而这多个容器在传统的调度工作中(比如像Docker Swarm,Mesos)都没有被妥善处理好,在进程组的调度上要么无法保障一个进程组的多个容器无法调度到同一个节点,要么调度的效率和性能的问题.
可在Kubernetes里,这个问题通过Pod完美解决了.Pod是kubernetes的原子调度单位,这就意味着Kubernetes是统一按照Pod而非单个容器的资源需求计算的.所以可以将多个容器部署在同一个Pod里,这些容器共享同一个Pod的网络名称,进程间通信,IP地址,共享卷等.而Kubernetes在调度时,会将他们作为一个整体,而非单个容器进程.
像这样容器间的紧密协作,我们可以称为“超亲密关系”。这些具有“超亲密关系”容器的典型特征包括但不限于:互相之间会发生直接的文件交换、使用 localhost 或者 Socket 文件进行本地通信、会发生非常频繁的远程调用、需要共享某些 Linux Namespace(比如,一个容器要加入另一个容器的 Network Namespace)等等。
这也就意味着,并不是所有有“关系”的容器都属于同一个 Pod。比如,PHP 应用容器和 MySQL 虽然会发生访问关系,但并没有必要、也不应该部署在同一台机器上,它们更适合做成两个 Pod。
不过,相信此时你可能会有第二个疑问:
对于初学者来说,一般都是先学会了用 Docker 这种单容器的工具,才会开始接触 Pod。
而如果 Pod 的设计只是出于调度上的考虑,那么 Kubernetes 项目似乎完全没有必要非得把 Pod 作为“一等公民”吧?这不是故意增加用户的学习门槛吗?
为了理解这一层含义,我就必须先给你介绍一下Pod 的实现原理。
POD实现原理
- Pod只是一个逻辑的概念
也就是说,Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。
那么,Pod 又是怎么被“创建”出来的呢?
答案是:Pod,其实是一组共享了某些资源的容器。
具体的说:Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
那这么来看的话,一个有 A、B 两个容器的 Pod,不就是等同于一个容器(容器 A)共享另外一个容器(容器 B)的网络和 Volume 的玩儿法么?
这好像通过 docker run –net –volumes-from 这样的命令就能实现嘛,比如:
1 | $ docker run --net=B --volumes-from=B --name=A image-A ... |
但是,你有没有考虑过,如果真这样做的话,容器 B 就必须比容器 A 先启动,这样一个 Pod 里的多个容器就不是对等关系,而是拓扑关系了。
所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:
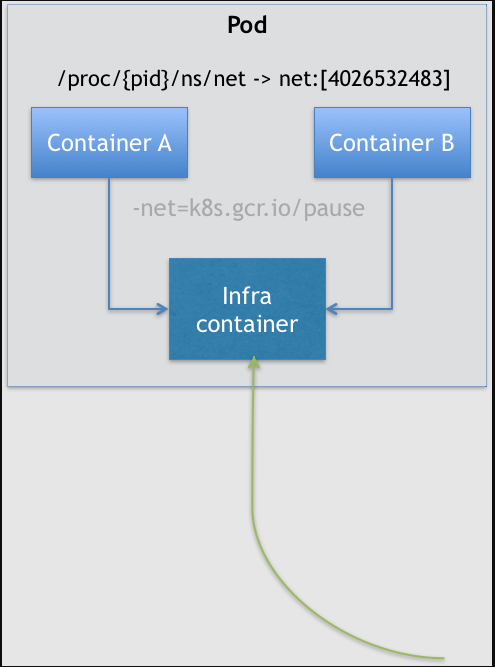
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件(这个 Namespace 文件的路径,我已经在前面的内容中介绍过),它们指向的值一定是完全一样的。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
容器设计模式
Pod 这种“超亲密关系”容器的设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
为了能够掌握这种思考方式,你就应该尽量尝试使用它来描述一些用单个容器难以解决的问题。
一个典型的例子就是容器的日志收集
比如,我现在有一个应用,需要不断地把日志文件输出到容器的 /var/log 目录中。
这时,我就可以把一个 Pod 里的 Volume 挂载到应用容器的 /var/log 目录上。
然后,我在这个 Pod 里同时运行一个日志收集客户端 容器,它也声明挂载同一个 Volume 到自己的 /var/log 目录上。
像这样,我们就用一种“组合”方式,解决了主容器和日志收集容器之间的耦合关系,而日志收集容器我们一般也称之为辅助容器.实际上,这个所谓的“组合”操作,正是容器设计模式里最常用的一种模式,它的名字叫:sidecar。顾名思义,sidecar 指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
这样,接下来 sidecar 容器就只需要做一件事儿,那就是不断地从自己的 /var/log 目录里读取日志文件,转发到 MongoDB 或者 Elasticsearch 中存储起来。这样,一个最基本的日志收集工作就完成了。

